Learning Spatiotemporal Features with 3D CNN
July 10, 2016 12:56 PM
Authors: Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, Manohar Paluri
1. Introduction
- 3 × 3 × 3 convolution kernel for all layers to work best.
2. Related Work
- Takes full video frames as inputs
- Doesn’t rely on any preprocessing
- 3D convolutions and 3D pooling
- Gradually pooling space and time information and building deeper networks achieves best result
3. Learning Features with 3D ConvNets
3D convolution and pooling
- 2D convolution (lose temporal information)
- 2D convolution on mutiple frames (lose temporal information)
- 3D convolution (preserves temporal information)
- Small receptive fields of 3×3 conv kernels with deeper architectures yield best result
Common network settings: UCF101 data set
- All frames are resized to 128×171
- Split into non-overlapped 16-frame clips
- Input dimentions: 3×16×128×171 (channels,length in number of frames,height,iwdth)
- 5 conv layers and 5 pooling layers
- 2 fully-connected layers and a softmax loss layer
- All convolution kernels have a kernel temporal depth
- Mini-batches: 30 clips
- Learning rate is divided by 10 after every 4 epochs
- Training is stopped after 16 epochs
- Not to merge the temporal signal too early
Varying network architectures
- Only vary kernal temporal depth d of the convolution layers
- depth=1 :2D
-
Different kernal temporal depth
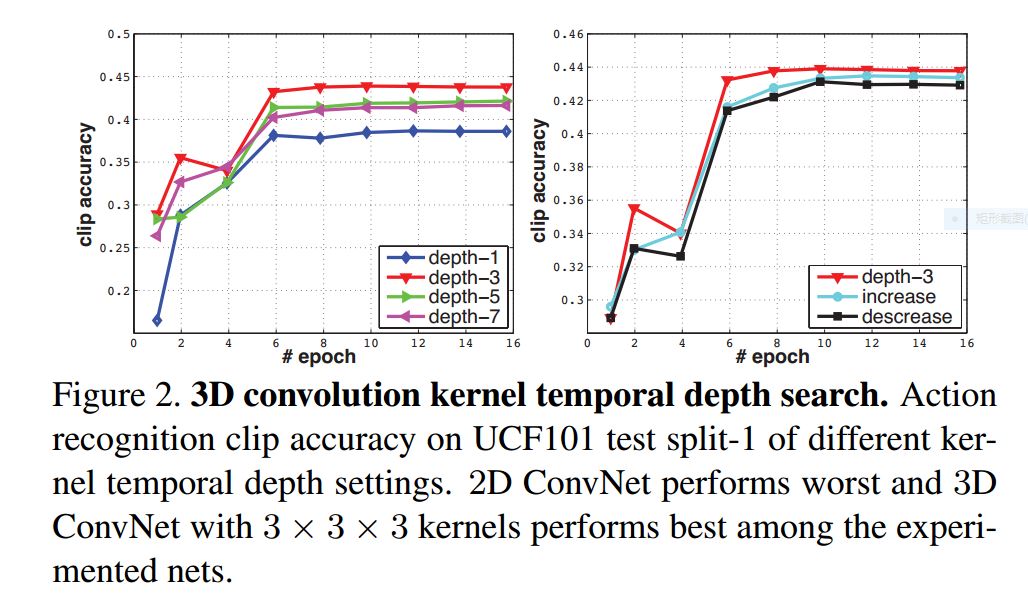
- homogeneous setting with convolution kernals of depth = 3 is the best option
Spatiotemporal feature learning
-
C3D architecture

- All 3D conv layers: 3×3×3 with stride 1×1×1
- All 3D pooling layers: 2×2×2 with stride 2×2×2 except for pool-1 (both kernel size and stride: 1×2×2)
- Deconvolution method to visualize the features M. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In ECCV, 2014. 5, 6, 9