Image style transfer using convolutional neural networks
Authors: Gatys Leon A,Ecker Alexander S.
常见的深度学习问题: 利用输入样本训练网络的权重,模型不断进化。
本文: 对于一个输出,利用已经训练好的权重(VGG19),得到一个符合要求的输入。模型不变。
1. 传统风格转换方法
很少涉及到高层特征,只利用了低层特征。因为缺乏语义信息所以很难将内容与风格区分开。
改进:
加入VGG19模型来提取高层特征
-
提取出目标图像的语义特征。
-
用从风格图像提取出的风格特征来渲染这些语义信息,得到输出。
2. 原始VGG19网络
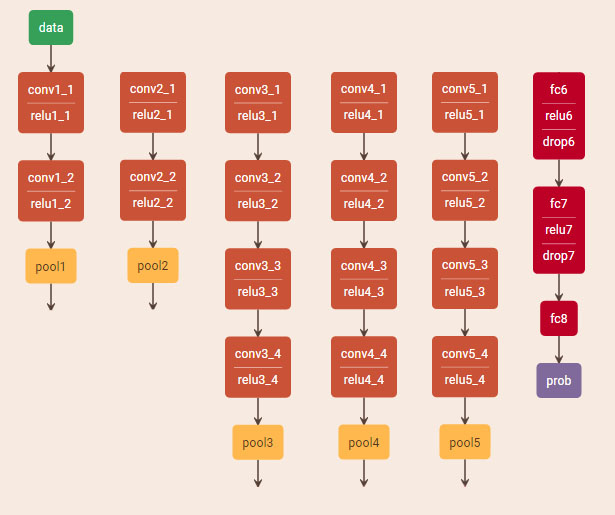
几点改进:
-
不用fc
-
max pooling 改为 average pooling
-
规格化每一层的权重,使每一层的每个filter的激活值的平均值位1
3. 算法框架
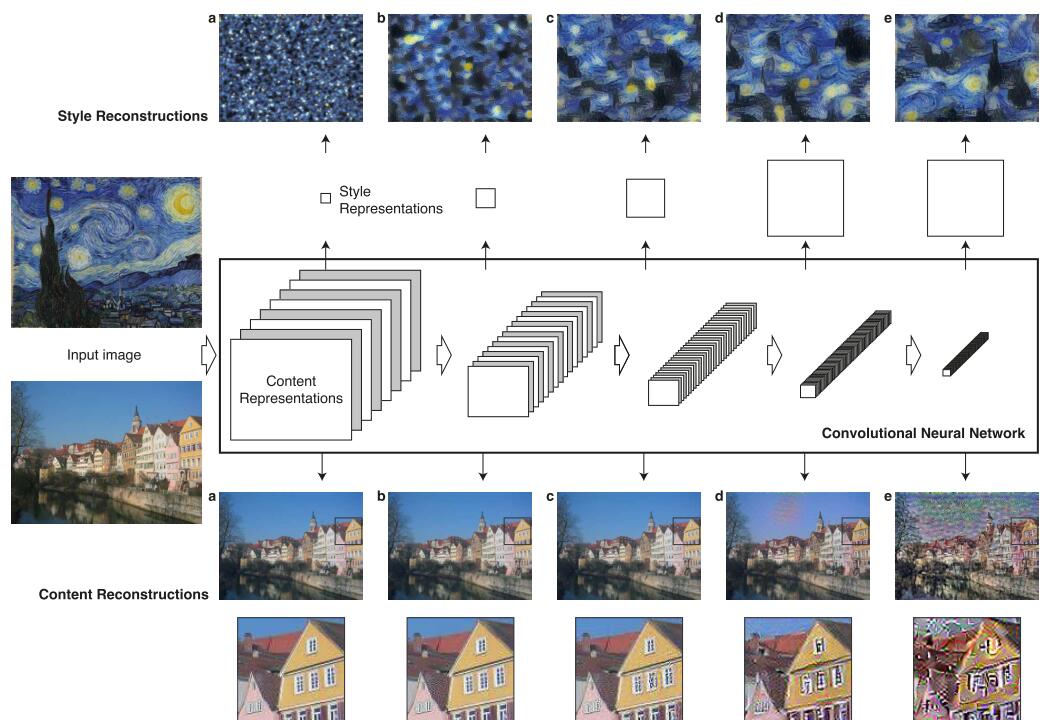
主要分为Content Reconstruction和Style Reconstructions
3.1 Content Reconstruction
提取网络中这5层的输出:
conv1_2 (a), conv2_2 (b), conv3_2 (c), conv4_2 (d), conv5_2 (e)
分别岁每层使用 Understanding-deep-image-representations-by-inverting-them 中的算法
3.2 Style Reconstructions
关注特征之间的关系。
使用Gram矩阵来表示特征之间的关系,$G_{ij}^l$表示第l层中特征i和j的内积。
将每一层的Gram加权相加后作为Understanding-deep-image-representations-by-inverting-them的输入得到风格特征的可视化。
Combining-Markov-Random-Fields-and-Convolutional-Neural-Networks-for-Image-Synthesis在这一步使用了MRF替代Gram,获得了更好的效果。
3.3 Style Transfer
其实就是将上述的style reconstruction 和 content reconstruction合二为一。
使用L-BFGS来进行优化。
4. Result
4.1 内容与风格的比重($\alpha/\beta$)

4.2 使用不同层

4.3 对真实照片的转化

目前对与content和style都是照片的情况表现不太好
-
照片尺寸一般较大,计算复杂
-
照片含有大量low-level noise