Style Transfer for Headshot Portraits
Authors: YiChang Shih,Sylvain Paris
0. Abstract
-
本文的方法能够将风格图像的局部对比度和整体的光照效果映射到内容图像上
-
提出了给定一张内容图片,从 一系列风格图片 中找到最适合用来风格转换一张的方法(比如对于一张有胡须的内容图片,就找到有胡须的风格图片)
最终结果效果图:

1. Introduction
过去的方法很多属于全局的风格转换,而在人脸的风格转换中细节很重要。
每一步的效果图:

Step1: 对齐人脸
-
人脸特征点检测:
检测到66个face landmark,这一步如果要自己实现,可以用AAM算法,或者用CNN,相关的人脸特征点检测的paper很多,近几年单单face++就发表了好几篇高精度人脸特征点检测的算法。基于CNN人脸特征点定位精度,从 Deep Convolutional Network Cascade for Facial Point Detection 的效果看是精度挺高的。
-
粗对齐:
以landmark为控制顶点,对Example图像进行变形,将特征点对齐。对齐算法采用 Feature-based image metamorphosis 这个变形算法。测试了一下,相比于 As-rigid-as-possible shape manipulation 和 Image Deformation Using Moving Least Squares 变形算法来说,其特点是可以实现保证图像人脸变形弧度比较大的时候,脸型的曲线过度比较自然。因此这个变形算法,可以用于瘦脸、眼睛放大等算法中。
-
精对齐:使用Dense sift flow进行对齐。
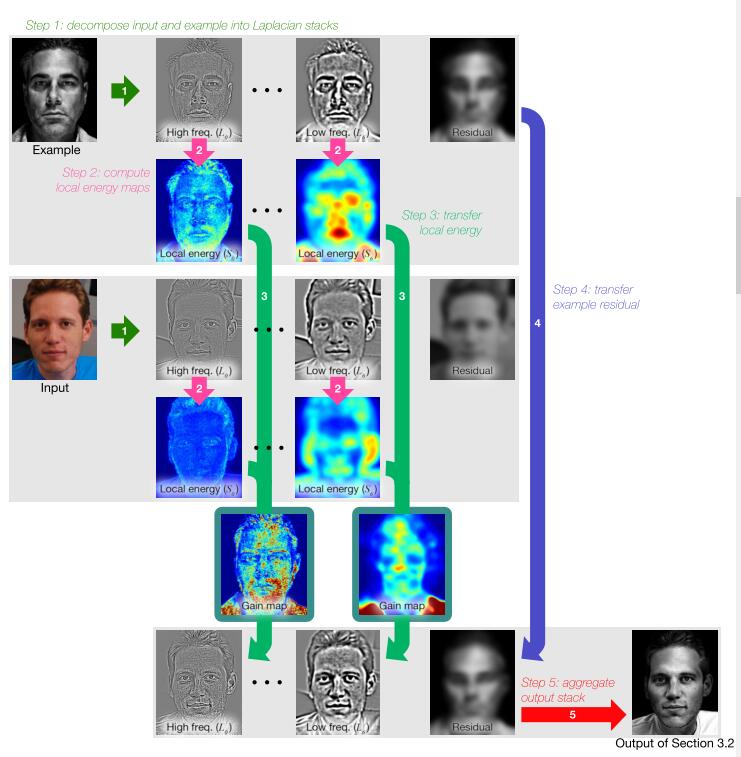
Step2:在多个scale上将风格图片的局部映射到内容图片
整个转换流程:
-
构建拉普拉斯金字塔
对内容和风格图像分别进行多尺度分解,构造拉普拉斯金子塔。
具体多尺度分解方法如下:
高斯卷积核的半径:第0,1,2,……层的卷积半径依次为2,4,8,…….
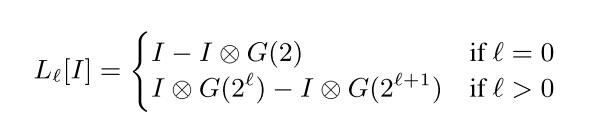
$I$代表输入图片,$G(2)$就是卷积半径为2的高斯核
卷积核大小的影响:

也就是用不同的卷积半径对一张图片分别进行卷积,然后进行相邻层之间相减,这样得到的多张图片就称之为金字塔了。这样把金字塔的每一层相加在一起刚好等于原图像$I$,这个过程称之为金字塔重建。
而金字塔融合的原理,就是对金字塔的每一层进行融合处理,然后进行重建。本篇paper实现光照风格转换的原理,就是对金子塔的每一层进行相关处理,然后再把处理后的每一层相加在一起,就可以得到重建结果。
Input、Example都要构建金字塔。本文选择了6层金字塔,还有最后一层为残差层。
-
计算金字塔每层的能量图
对于Input image:对金字塔的每一层平方,然后在进行高斯卷积。得到的图像称为能量图。
对于Example image:先要计算出每一层的能量图,然后进行变形。
-
对Input image金子塔的每一层(除了最后一层残差层之外),进行风格转换
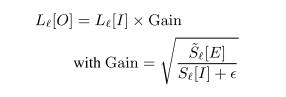
2. RelatedWork
-
Example-based Face Enhancement
Joshi et al. [2010] and An and Pellacini [2010] successfully transfer color balance and overall exposure.
Tong et al. [2007] and Guo et al. [2009] transfer make-up.
Brand and Pletscher [2008] and Leyvand et al. [2008] improve face appearance.
In comparison, we focus specifically on photographic style transfer, including aspects such as skin texture, local contrast, and light properties.
-
Face Synthesis
Our work is related to face synthesis [Liu et al. 2007; Mohammed et al. 2009] in that we generate a portrait that can differ dramatically from the input.
However, unlike Mohammed et al. [2009], we seek to retain the identity of the person shown in the input photo. Liu et al. [2007] do that, but consider the different problem of resolution enhancement.
-
Face Relighting
Altering the illumination on a face is a common operation for face recognition and video editing, e.g., [Wen et al. 2003; Zhang et al. 2005; Peers et al. 2007].
In comparison, we focus on photographic style. While this may involve some illumination change, it is not a primary objective of our work and we do not claim a contribution in this area.